
데이터 출처
Mobile Device Usage and User Behavior Dataset
Analyzing Mobile Usage Patterns and User Behavior Classification Across Devices
www.kaggle.com
과정 tmi
처음에는 해당 데이터로 스마트폰 제조사별 사용 실태를 보기 위한 대시보드를 만드려고 했다.
인터넷에서 20대는 아이폰 쓴다~ 이러는 말들이 생각나서 한번 대시보드로 만들어 보고 싶었다.
그래서 이하와 같은 구성안도 짜뒀음!
남성, 여성별 사용 브랜드 점유율을 보고 해당 브랜드를 누르면 ,브랜드를 선호하는 나이대별 비율이 나오고,
나이대를 누르면 선호하는 기종이 순위별로 나오게끔 하고 싶었다
근데 아뿔싸,,, 사용 핸드폰 종류가 브랜드별로 1개씩만 있지 머야,,, 그래서 해당 구성안은 안뇽이 되어버렸다 쩝,,
해당 데이터로는 어떤걸 나타낼 수 있을까 다시 고민하다가 유저별 스크린타임 컬럼을 보게 되었고, 그냥 user behavior 파트에만 집중해보기로 함.
스크린타임과 관련해 생각해보니, 스마트폰 사용의 고전적 문제점인 과도한 사용이 떠올랐고 그와 관련된 대시보드를 만들어보았다.
대시보드
목적 : 연령대 및 성별 별 스마트폰 과의존 위험군 수를 파악하고, 대상자들이 스마트폰을 얼마나 사용하고 있는지를 확인하기 위함
이를 위해 '스크린타임이 어느 정도면 과의존이다' 라는 것을 판단하기 위한 기준이 필요했고, 이하와 같은 자료를 찾아 해당 자료를 기반으로 과의존의 기준을 삼았다.
스마트폰 중독과 사용 방법
[BY 보험비교전문몰] 출퇴근길에 사람들의 모습을 본 적 있으신가요? 하나 같이 손바닥 만한 스마트폰에...
m.post.naver.com
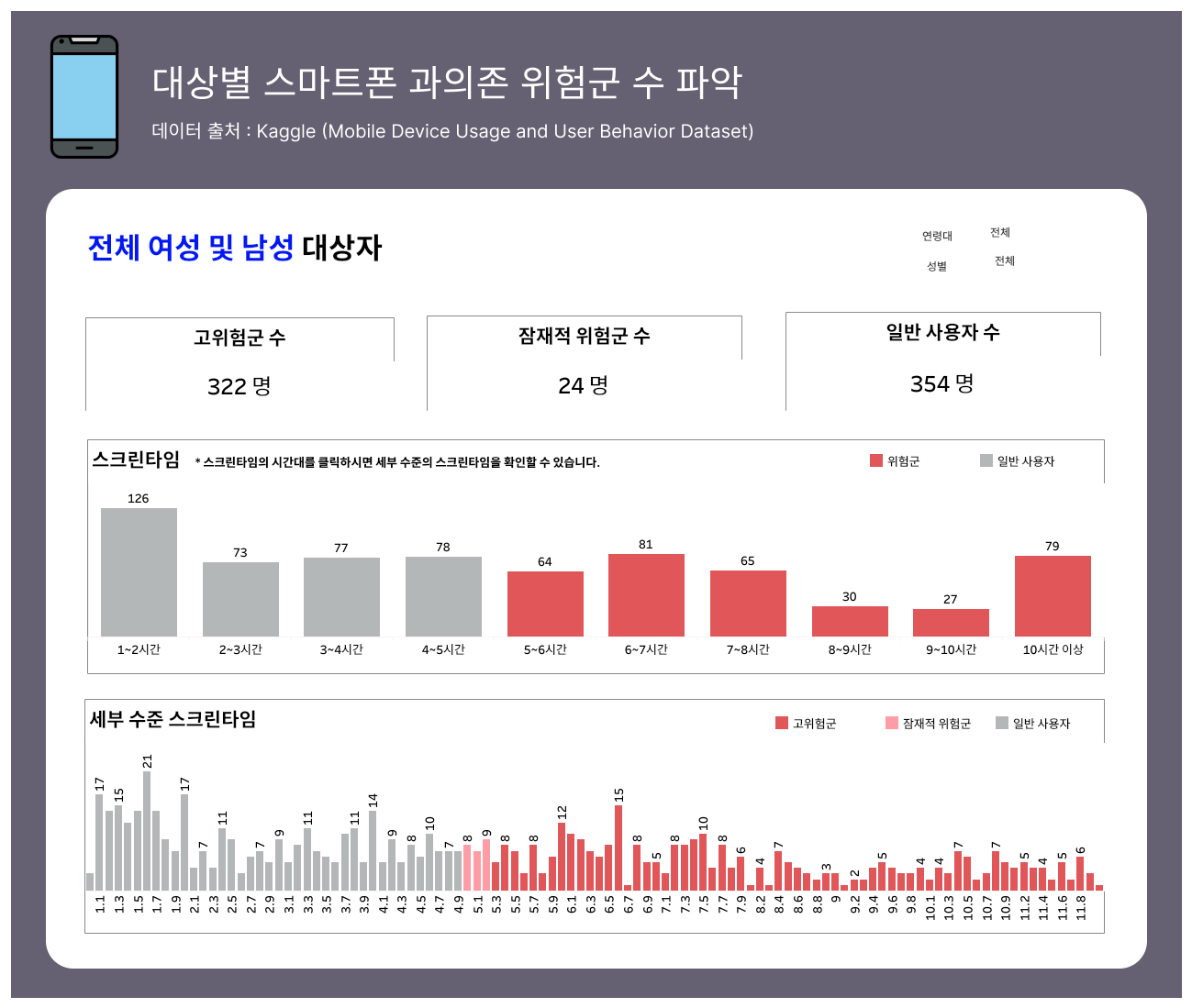
1. 필터와 제목을 연동시켜 현재 보고 있는 대상자 그룹이 무엇인지 확실히 볼 수 있도록 함
2. 위험군 수 / 잠재적 위험군 수 / 일반 사용자 수 라인 : 위험군 분류별로 대상자 수가 얼마나 있는지 한눈에 보여주기 위함
3. 스크린 타임 : 해당 스크린 타임에 대상자들이 얼마나 분포하고 있는지 보여주기 위함 / 시간 단위로 스크린타임을 나눠 분포를 크게 파악할 수 있도록 함
+) 고 위험군과 잠재적 위험군의 차이가 10분 차이로 나눠지기 때문에 시간 단위 스크린 타임에서는 위험군과 일반 사용자로 구분함
4. 세부 수준 스크린 타임 : 스크린타임을 두번 클릭하면 세부 수준 스크린 타임에 필터가 걸리게 해둬, 원하는 시간대 안에서의 분 단위의 분포도를 확인할 수 있음
데이터 출처
Mobile Device Usage and User Behavior Dataset
Analyzing Mobile Usage Patterns and User Behavior Classification Across Devices
www.kaggle.com
과정 tmi
처음에는 해당 데이터로 스마트폰 제조사별 사용 실태를 보기 위한 대시보드를 만드려고 했다.
인터넷에서 20대는 아이폰 쓴다~ 이러는 말들이 생각나서 한번 대시보드로 만들어 보고 싶었다.
그래서 이하와 같은 구성안도 짜뒀음!
남성, 여성별 사용 브랜드 점유율을 보고 해당 브랜드를 누르면 ,브랜드를 선호하는 나이대별 비율이 나오고,
나이대를 누르면 선호하는 기종이 순위별로 나오게끔 하고 싶었다
근데 아뿔싸,,, 사용 핸드폰 종류가 브랜드별로 1개씩만 있지 머야,,, 그래서 해당 구성안은 안뇽이 되어버렸다 쩝,,
해당 데이터로는 어떤걸 나타낼 수 있을까 다시 고민하다가 유저별 스크린타임 컬럼을 보게 되었고, 그냥 user behavior 파트에만 집중해보기로 함.
스크린타임과 관련해 생각해보니, 스마트폰 사용의 고전적 문제점인 과도한 사용이 떠올랐고 그와 관련된 대시보드를 만들어보았다.
대시보드
목적 : 연령대 및 성별 별 스마트폰 과의존 위험군 수를 파악하고, 대상자들이 스마트폰을 얼마나 사용하고 있는지를 확인하기 위함
이를 위해 '스크린타임이 어느 정도면 과의존이다' 라는 것을 판단하기 위한 기준이 필요했고, 이하와 같은 자료를 찾아 해당 자료를 기반으로 과의존의 기준을 삼았다.
스마트폰 중독과 사용 방법
[BY 보험비교전문몰] 출퇴근길에 사람들의 모습을 본 적 있으신가요? 하나 같이 손바닥 만한 스마트폰에...
m.post.naver.com
1. 필터와 제목을 연동시켜 현재 보고 있는 대상자 그룹이 무엇인지 확실히 볼 수 있도록 함
2. 위험군 수 / 잠재적 위험군 수 / 일반 사용자 수 라인 : 위험군 분류별로 대상자 수가 얼마나 있는지 한눈에 보여주기 위함
3. 스크린 타임 : 해당 스크린 타임에 대상자들이 얼마나 분포하고 있는지 보여주기 위함 / 시간 단위로 스크린타임을 나눠 분포를 크게 파악할 수 있도록 함
+) 고 위험군과 잠재적 위험군의 차이가 10분 차이로 나눠지기 때문에 시간 단위 스크린 타임에서는 위험군과 일반 사용자로 구분함
4. 세부 수준 스크린 타임 : 스크린타임을 두번 클릭하면 세부 수준 스크린 타임에 필터가 걸리게 해둬, 원하는 시간대 안에서의 분 단위의 분포도를 확인할 수 있음