
t-test를 이해하는 데 앞서, 정규분포와 z-test를 먼저 이해하는 게 좋다.
모집단의 경우에는 z-test를 하고 샘플의 경우에는 t-test를 하는 것이므로, 정규분포와 z-test에 대한 이해가 선행되면 t분포와 t-test에 대한 이해가 쉽기 때문!
정규분포

- 정규분포의 특징
- 종모양을 갖는다
- 평균 (정가운데)를 중심으로 좌우 대칭이다
- 정규분포의 양 끝은 영원히 0에 닿지 않는다
- 정규분포는 평균과 표준편차만으로 규정된다, 즉 평균과 표준편차가 다르다면, 서로 다른 정규분포가 무한대 존재하게 된다.
- 정규분포의 아래 면적은 확률을 의미한다.
- 정규분포 곡선 아래의 모든 면적의 합은 1이다.
- 이에 정규분포를 이용한 확률을 구하려면 적분을 해야하는데, 확률 구하려고 적분을 하나하나 하는건 비효율의 끝판왕이라고 할 수 있다.
따라서, 이를 극복하고자 나온 것이 바로 표준정규분포이다.
표준정규분포
무한대 가지의 정규분포 곡선을 적분하는 번거로움을 없애기 위해 나온 것이 표준정규분포로,
표준정규분포는 평균이 0이고, 표준편차가 1인 정규분포이다. 이러한 표준정규분포를 어떻게 사용할 수 있을까?
표준정규분포 사용 예시
1000명을 대상으로 영어 실력고사를 시행했을 때, 평균 점수가 82점이고 표준편차가 5가 나왔고, (영어 점수의 분포는 정규분포에 근사)
82점부터 90점까지 점수를 받은 학생 수를 구하고자한다.
근데 이때 정규분포를 사용하게 되면 82점~90점 사이의 면적을 적분을 통해서 구하고 1000명을 곱해서 학생수를 구해야한다. 벌써부터 머리가 아프다.
하지만, 이를 표준정규분포로 전환한다면 보다 쉽게 학생수를 구할 수 있다.
정규분포를 표준정규분포로 바꾸는 공식은 다음과 같다.

따라서, 저 영어 점수에 대한 분포를 표준정규 분포로 바꾸면 다음과 같다.

이제 알아야할 건 " ? " 면적이다. 이 면적은 표준정규분표포를 통해 구할 수 있다 (* 면적 = 확률)
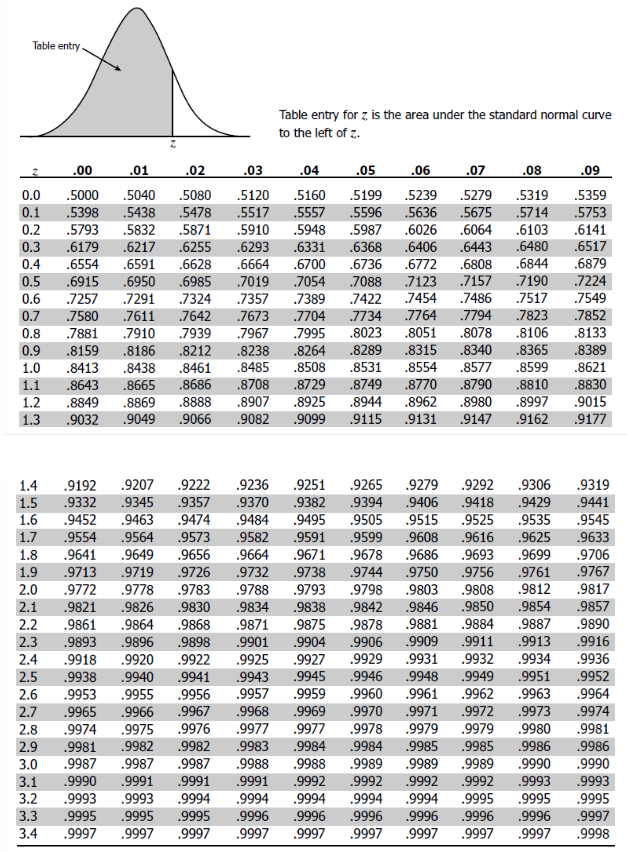
표준정규분표는 끝에서 우리가 원하는 값까지의 확률을 구해준다.
여기서 세로는 소수점 첫째자리고 가로는 소수점 둘째자리임!
따라서 저 끝에서 1.6 까지에 대한 면적, 즉 확률은 0.9452다.
하지만 우리가 원하는건 0~1.6까지의 확률이므로 절반값인 0.5을 빼준 0.4452가 되고, 0.4452 * 1000을 한 445명이 구하고자한 학생수이다.
이러한 z-score (z값)을 가지고 하는 테스트가 바로 z-test이다.
z-test
z-test는 z-score과 표준정규분포표를 이용하여 할 수 있다.
이러한 z-score는 1 표준편차당 관찰값(X)가 평균으로부터 얼마나 떨어져있는지를 의미한다.
* z-score은 단위로부터 자유로워서 단위를 신경쓰지 않아도 됨
결론은 무엇인가?
t-test를 하는데 표준정규분포표 z-test를 말하는게 뭔가 싶지만 정규분포표로 구한 면적, 즉 확률이 우리가 앞서 말했던 확률과 같다.
앞선 포스팅에서 1.4cm란 키차이가 우연히 발생했을 확률은 얼마나 될까? 라고 했을 때의 확률이 바로 분포표로 구한 면적 (=확률)과 같은 것이다.
즉, 이렇게 구한 확률이 유의수준 0.05보다 작으면 우연이 아니라고 보고, 0.05보다 크면 우연이라고 보는 것이다.
* t-test는 정규분포가 아닌 t분포를 활용하기만 개념은 같음
출처
- Sapientia a Dei
t-test (t-검정)이란 무엇인가?
t-test (t-검정)에 대한 동영상 모음
www.youtube.com